AI is chasing the judgment happening in this exact second.
It will never fully catch it. Not because of compute. Not because of data volume. Because human judgment is not just an output. It is a situated act.
A human expert does not judge from nowhere. She judges from inside a specific body of experience, a specific context, a specific set of stakes, and a specific relationship to consequence. Heidegger called this thrownness — the condition of always already being somewhere, never nowhere.
That is why expert judgment cannot be separated from the one who judges. It is not a function that runs on any substrate. It is an act performed by someone who is somewhere, who has lived something, and who stands to lose something if she is wrong.
AI can produce outputs that resemble judgment. But it does not occupy the situation from which judgment emerges.
It has processed everything and inhabited nothing.
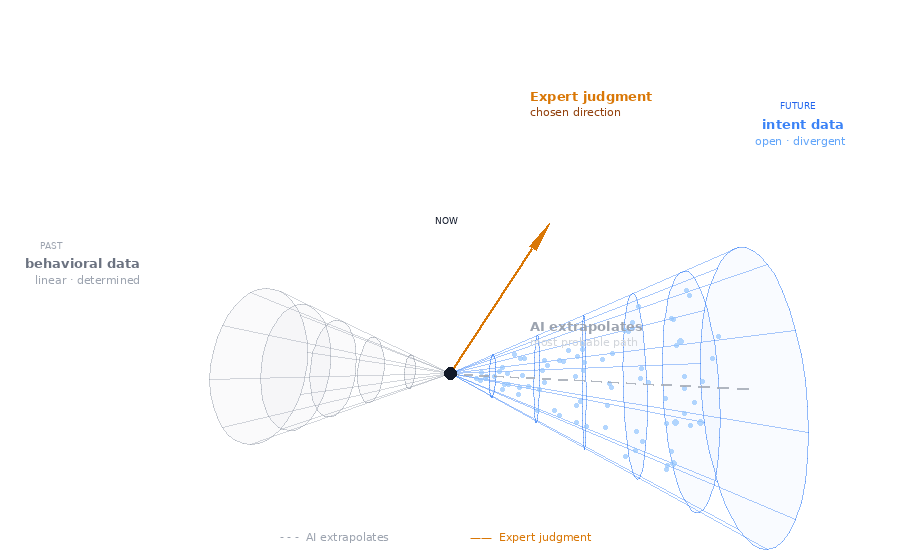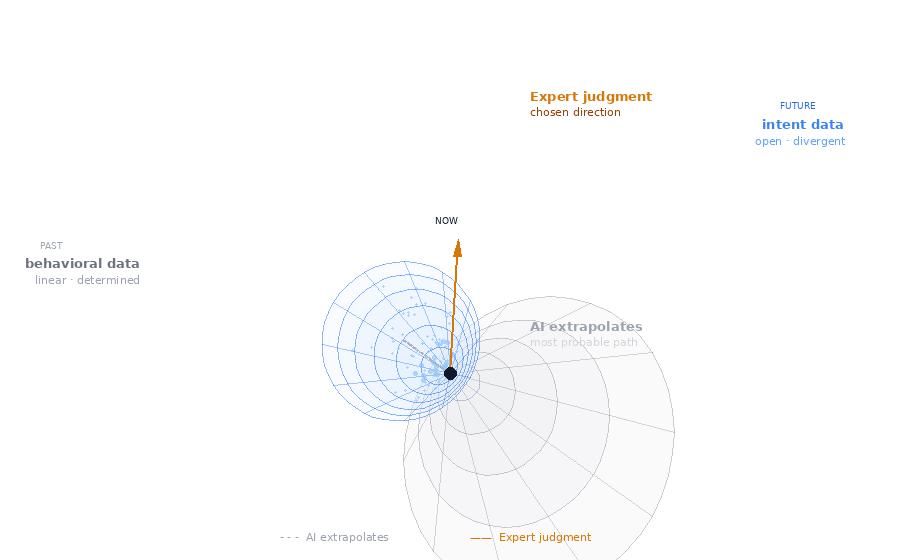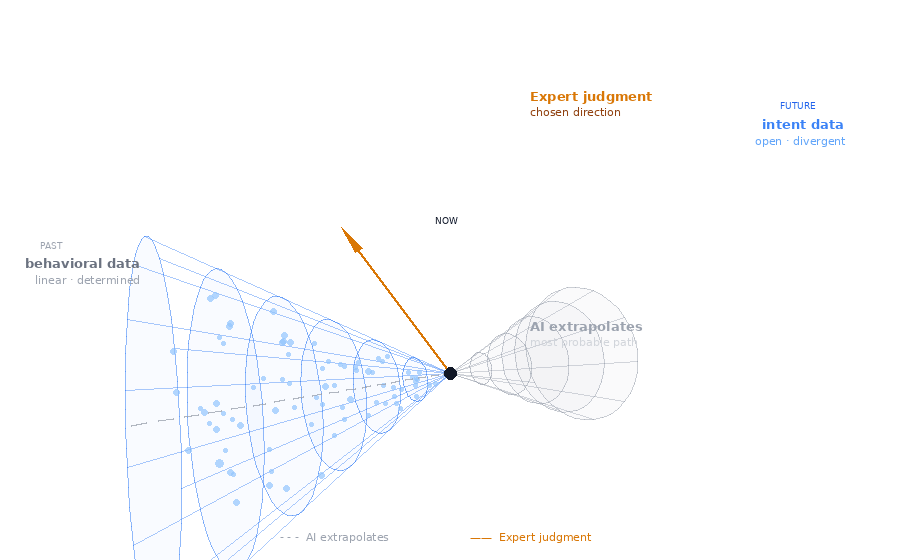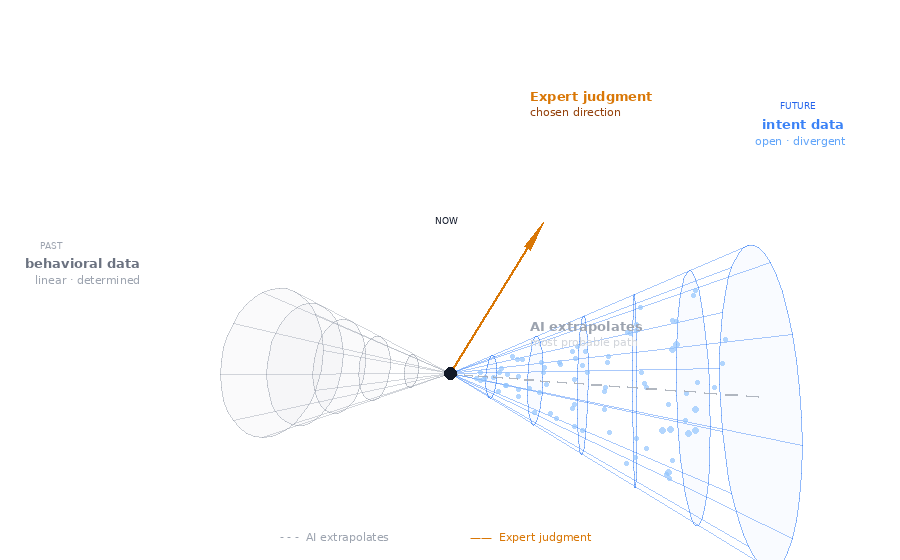
Two kinds of data. The past is fixed. The future is open.
Behavioral data is what most AI systems run on: the record of what has already occurred. What was clicked, viewed, purchased, returned. It is generated automatically, as a byproduct of interaction.
The past is linear: events have resolved into a single determined path.
The future is not. From any given moment, an open field of possibilities extends outward, divergent, branching, not yet resolved. To get to a specific point inside that field, you have to navigate. And navigation requires a direction.
That direction is what expert judgment produces. When a buying director decides what to bring in for next season, she isn't just extrapolating from the past. She is pointing into an open space, toward something that doesn't exist yet but should. That act of pointing, made before any outcome exists to confirm or deny it, is a different kind of data entirely.
Behavioral data: the record of what has occurred.
Expert judgment data: a judgment about what should occur - a direction chosen inside an open future.
One captures a determined past. The other navigates an open future. They don't just differ in quality. They operate in different kinds of space.
Two different goals
When you have enough ground truth (browsing history, purchase history, demographic signals), AI is smart enough to do something genuinely impressive - and will be smarter. It can “predict” what a user is most likely to accept next.
This is not a small thing. But it is a linear thing.
In Anthropic's Project Deal experiment, a Claude agent successfully modeled an employee's preferences well enough to purchase him a snowboard. The problem: he already owned the exact same one. The agent had optimized for what he would accept. It had no way of knowing what he actually needed next, or whether this was even the right moment, the right product, or the right ceiling for this person's spending.
This is the structural gap.
AI optimizes for acceptance which is the most probable yes.
While expert judgment starts from the same ground truth but adds a layer AI cannot reach.
A high-touch sales advisor is not only gauging what the client will accept. She is deciding where the client should go next. That judgment is never in service of a single intention - it simultaneously carries taste, timing, risk, relationship, occasion, and commercial stake. When she pulls a piece for a client, that one act is at once educational (expanding what the client believes is possible for them), commercial (moving what the business needs to move), and an expression of brand POV (asserting where this label is taking its customer next). These intentions do not take turns. They arrive together, or not at all.
A financial advisor works the same way. She isn't recommending the product with the highest historical acceptance rate. She's making a judgment about what this client is ready for, what fits their life in ways they haven't fully articulated, and where the relationship needs to go.
These goals sometimes overlap. When they do, AI performs well. When they diverge, which is exactly when the highest-value decisions happen, the gap becomes structural.
Not because AI lacks dimensions. AI has many: co-occurrence patterns, behavioral sequences, demographic signals, session context, recency, frequency. These are real. They are sophisticated. But every one of them points in the same direction: backward. Each is a different way of asking the same question: what have people like this accepted before?
The expert starts from the same facts. Then adds a layer AI cannot reach: taste trajectory, not just taste history; readiness, not just recency; relational risk; commercial alignment; what this person should encounter next - not what they've said yes to before. It’s directional.
The State of the art
If expert judgment adds a layer AI cannot reach, the obvious question is: why not simply direct AI toward it? The obvious approach is to ask experts to explain themselves. Annotate, encode and feed it to the system.
Dreyfus spent decades showing why this fails. His argument is not that expert knowledge is too complex to capture. It is that expertise, at its highest levels, is no longer rule-following at all. When knowledge engineers ask experts to articulate their rules, they fail — because the expert is "not following any rules." Ask anyway, and you force the expert to regress: to retrieve the explicit principles she learned as a beginner, principles she has long since stopped using. What you capture is not expertise. It is its ghost.
In practice across medicine, law, wealth management, and retail, the dominant narrative is augmentation: AI should enhance expert judgment, not replace it. The AMA states that AI must "enhance — not replace — physicians." Thomson Reuters says the future of legal AI "lies not in replacing attorney judgment but in augmenting it." McKinsey argues that replacing tasks "is not the same as replacing the advisor's role.”
But knowing that expert judgment is irreplaceable is not the same as capturing it.
Most enterprise AI systems are built to learn from outcomes, clicks, labels, and acceptance rates. Expert judgment enters the workflow as a final check — a veto, a correction, a safeguard when the system fails.
Placing a human "in the loop" sounds like preserving judgment. In practice, it often means something narrower: a validator checking machine output, not an expert exercising genuine directional authority. The loop is designed for exception handling, not for learning.
It is treated as a temporary safety layer. As hidden labor that keeps brittle automation functional.
Not as a compounding enterprise asset.
The Vanishing Point
Most organizations have no mechanism fundamentally for capturing expert judgment in real time. It happens and is gone. It cannot be reconstructed after the fact.
You can record what the buyer ordered. You cannot recover why she passed on the other options. The signal lives in the decision itself. The obvious workaround is annotation: ask the expert to explain their choice after the fact. The act of asking an expert to stop and explain their choice alters the cognitive state that produced it. What you capture is a rationalization. Not the judgment.
There are also other reasons organizations give for not capturing it: expert judgment is too noisy to learn from; it’s not ground truth; it cannot compound reliably. These are real concerns. They are also engineer problems that can be solved.
Expert judgment can only be captured at the moment it occurs, inside the tools the expert is already using, with zero interruption to the cognitive state that produced it. This is not a design preference but the only condition under which what you collect is still judgment rather than a reconstruction of one.
The architecture has to be: build the tool the expert needs to do their job, and let the data be a byproduct of the work itself.
In one high-touch sales workflow I built, the pattern became clear. When advisors curate, sequence, and send recommendations inside a tool designed for the work itself, those actions generate structured expert judgment data without requiring annotation. The capture is a byproduct of the work. That is the only architecture that preserves what it measures.
The architecture exists. It is detailed across three whitepapers.
The first describes a tool built as a primary production surface for high-touch client sales: selecting products, arranging them, writing a message, and sending to selected clients at a chosen moment. As she works, the system quietly records what she chose, how she arranged it, who she sent it to, and how the client responded. The data is a byproduct of the work. She never has to stop and explain herself.
The second builds an operating intelligence layer across the department's recurring judgment-heavy work. For each judgment moment in high-touch sales — a client briefing, a retention decision, an approval call, a prospecting review — the system assembles the relevant context from across the organization and surfaces it at the right moment. The expert makes the call. The system records it. The judgment that used to live only in someone's head, or disappear when they left, becomes part of how the department operates.
The third is where the learning happens. It connects the relevant captured judgments, enterprise context, and what actually happened after into a single structure that updates two things simultaneously. The first is a working picture of how products function in real expert-led selling: which pieces anchor a selection, which complete it, which travel across client types and which do not, and what framing makes them work. The second is a context-specific read on where clients and segments actually are — not a static profile score, but a live understanding of readiness, saturation, timing, and relationship state. When the system begins proposing selections and experts modify them, those modifications become the richest signal of all: the precise gap between what the system thinks is right and what the expert judges to be right. That gap, accumulated over time, makes the organization’s commercial belief visible for the first time.
The full architecture is in the whitepapers. What they do not fully address is what makes or breaks the attempt.
The tool has to earn its place.
Zero friction is an epistemic constraint. It is also an adoption constraint.
A capture layer that experts don't use generates nothing. And asking a business-side team to adopt a new tool — even a well-designed one — is one of the hardest problems in enterprise software. The failure mode is not technical. It is behavioral: the tool exists, the data model is correct, and the system sits unused because the people it was built for found a way around it.
The only architecture that survives this is one where the tool's reason to exist has nothing to do with data capture. It is either a meaningful improvement on something the team already uses, or the answer to a need the team has been articulating for months with no one having built it yet. The advisors adopt it because it solves something real for them — and would use it even if no one was watching, even if no system was recording anything. That is the only adoption condition that holds.
When that condition is met, capture becomes a byproduct. When it isn't, capture is a tax — and taxes get avoided.
This is not a design preference. It is the precondition for everything else.
The system is also a judgment development infrastructure.
Thomson Reuters' 2025 Future of Professionals report identifies the risk directly: AI is being deployed most heavily to automate the entry-level work where professional judgment is built. A 2026 SSRN preprint extends the argument further that organizations automating away the formation of expertise may eventually lose the capacity to govern AI itself.
The problem is the same: AI is automating entry-level work, and entry-level work is where judgment gets built. Junior advisors learn to curate by curating badly and being corrected. Junior analysts learn to read a situation by making the wrong call and understanding why. When automation removes those formative tasks, the cultivation path disappears with them. Organizations end up with experienced experts who cannot be replaced, and no pipeline to replace them.
The architecture described in these whitepapers closes that gap - not as a side effect, but structurally.
Different experts make different judgments. A junior advisor and a senior advisor, given the same client context and the same system proposal, will modify it differently. Capture both. Over time, compare their interventions against outcome evidence, peer review, and repeated patterns. The senior override may carry more signal; the junior override, compared against the senior's, reveals the gap between them.
That gap is not noise. It is the most precise description of what the junior advisor has not yet learned to see.
The diff between junior and senior expert interventions is a structured apprenticeship curriculum — one that has always existed implicitly in every high-touch organization, and has never before been legible. The system does not just capture judgment. It makes the development of judgment visible, measurable, and transferable in a way that does not depend on proximity, memory, or a senior advisor's willingness to explain herself.
Someone has to own this and say so.
The whitepapers have a governance section. It specifies who owns what. It does not say why ownership is the thing that fails first.
Business stakeholders have to define the capabilities themselves. Not delegate to a technical partner, not approve a spec written by someone else. They have to articulate, in their own language, what the recurring work is, what a good decision looks like, what should never be automated, and what the system is allowed to learn from. When that work is done by technical owners instead, the result is a system that captures the wrong moments, with the wrong structure, for learning objectives that no one on the business side recognizes as theirs.
The second decision is harder: where does human judgment stay in the loop permanently, where does it phase out, and where does it operate in copilot mode indefinitely? This is not a technical question. It is a values question that organizations avoid making explicit — and pay for in adoption failures, expert distrust, and data that encodes the wrong thing.
And underneath both decisions is a commitment that has to be made before the system is built, not after it starts working: the experts whose judgment is being captured will not be automated out of existence. This is not only an ethical position. It is a data quality constraint. Experts who believe they are annotating their own replacement will perform for the system, not inside it. The judgment you capture will be theater.
The architecture only works if the organization is willing to name what it is: a system where human expertise and machine learning compound together, where the expert becomes more valuable as the system becomes more precise, and where the data that cannot be bought, scraped, or synthesized is governed with the people whose judgment produced it.
That is the compact. But it has to be said out loud before anyone is asked to trust the system.
Until now, expert judgment has been a personal asset that the organization rents. It lives in the expert - in her sense of timing, her read on the client, her instinct about which direction the brand should take. When she leaves, it leaves with her. When she is unavailable, it is unavailable. When she is wrong, the organization has no way to know until the consequences arrive.
The asset is not the expert’s private intuition extracted after the fact. It is the execution-linked trace of judgment captured inside real workflow, joined later with outcome evidence.
What this system produces, over time, is something that has never existed before: expert judgment as an institutional asset. Not a record of decisions, but a structured, compounding body of knowledge about how good judgment actually works: which kinds of judgment become reliable in which contexts, where the organization's commercial instincts are sharp and where they drift toward average, what the market has not yet resolved that your best people can already see.
The first time a junior advisor's modification diverges from a senior's in a measurable, recurring way, that divergence is information the organization has never had access to before. The first time the system's proposal is overridden in a pattern that holds across dozens of clients and three quarters, that pattern is something no behavioral data could surface. The first time a client responds to a direction the system would never have chosen, that response is evidence that the organization's POV differs from the market's — and in which direction.
This is what compounds.
The Validation Loop
Expert judgment is a snapshot of a future that doesn’t exist yet.
When that future arrives, the snapshot meets its outcome. This is not performance tracking. It is the moment a forward-facing judgment encounters reality and the gap between them becomes measurable.
Over time, this builds a new institutional capability, not only a record of what experts chose, but a model of how judgment performs under specific conditions: which judgments tend to hold, where human expertise is irreplaceable, and where it has blind spots.
Once there is a baseline, rejection becomes one of the highest-value signals. A stylist curating from scratch leaves no trace of what she considered and set aside. A stylist responding to a system proposal makes her rejections explicit. Every rejection encodes judgment. Every modification reveals the gap between what the system predicts and what the expert chooses to stand behind
That gap is the most precise measurement of where an organization’s POV diverges from average. It is differentiation made visible.
The Moat
Expert judgment data compounds differently from other enterprise AI assets.
It gets richer as your experts develop sharper judgment. It gets more precise as the system generates more proposals for experts to respond to. It cannot be purchased, scraped, or synthesized. It only exists in the moment of judgment, inside the thrown situation of a specific person doing specific work.
And it solves something compute cannot solve: the gap between what your customers have done and what they are ready for next. The gap between what the market has averaged and what your organization actually believes.
The Question
Your experts are making judgments right now. Each one is a thrown subject reaching toward a future that doesn’t exist yet, deciding what it should become.
In one hour, that act will be gone.
What would it be worth to have caught it?
American Medical Association. (2026, March 12). AMA: AI usage among doctors doubles as confidence in technology grows. https://www.ama-assn.org/press-center/ama-press-releases/ama-ai-usage-among-doctors-doubles-confidence-technology-grows
Anthropic. (2026). Project Deal: Our Claude-run marketplace experiment. https://www.anthropic.com/features/project-deal
Dreyfus, H. L. (1972). What Computers Can't Do: A Critique of Artificial Reason. Harper & Row.
Dreyfus, H. L. (1987). From Socrates to expert systems: The limits of calculative rationality. Bulletin of the American Academy of Arts and Sciences, 40(4), 15-31.
Dreyfus, H. L. (1992). What Computers Still Can't Do: A Critique of Artificial Reason. MIT Press.
Dreyfus, H. L. (2007). Why Heideggerian AI failed and how fixing it would require making it more Heideggerian. Artificial Intelligence, 171(18), 1137-1160. https://doi.org/10.1016/j.artint.2007.10.012
Heidegger, M. (1962). Being and Time (J. Macquarrie & E. Robinson, Trans.). Harper & Row. (Original work published 1927)
McKinsey & Company. (2026, April 8). The signal in the sell-off: Wealth management's value in the AI era. https://www.mckinsey.com/industries/financial-services/our-insights/the-signal-in-the-sell-off-wealth-managements-value-in-the-ai-era
Sze, G. (2026, April 20). The accountability vacuum: Why agentic AI governance fails under conditions of expertise erosion. SSRN. https://ssrn.com/abstract=6610518
Thomson Reuters Institute. (2025). Future of Professionals Report 2025. Thomson Reuters. https://www.thomsonreuters.com/en/c/future-of-professionals
Thomson Reuters Institute. (2025, April 15). 2025 Generative AI in Professional Services report: Executive summary for legal professionals. Thomson Reuters Legal. https://legal.thomsonreuters.com/blog/genai-report-executive-summary-for-legal-professionals-tri/